
Introduction
How neural networks work for beginners, including layers, weights, training, inference, examples, and the practical limits behind the core terminology. are especially useful when simpler linear approaches are not enough and when feature interactions become too complex to encode manually.
This article was reviewed against official framework and educational documentation available on March 10, 2026. If you want one short answer, a neural network is a set of layers that repeatedly apply weighted math and activation functions so the model can learn better internal representations from examples.
What a neural network is
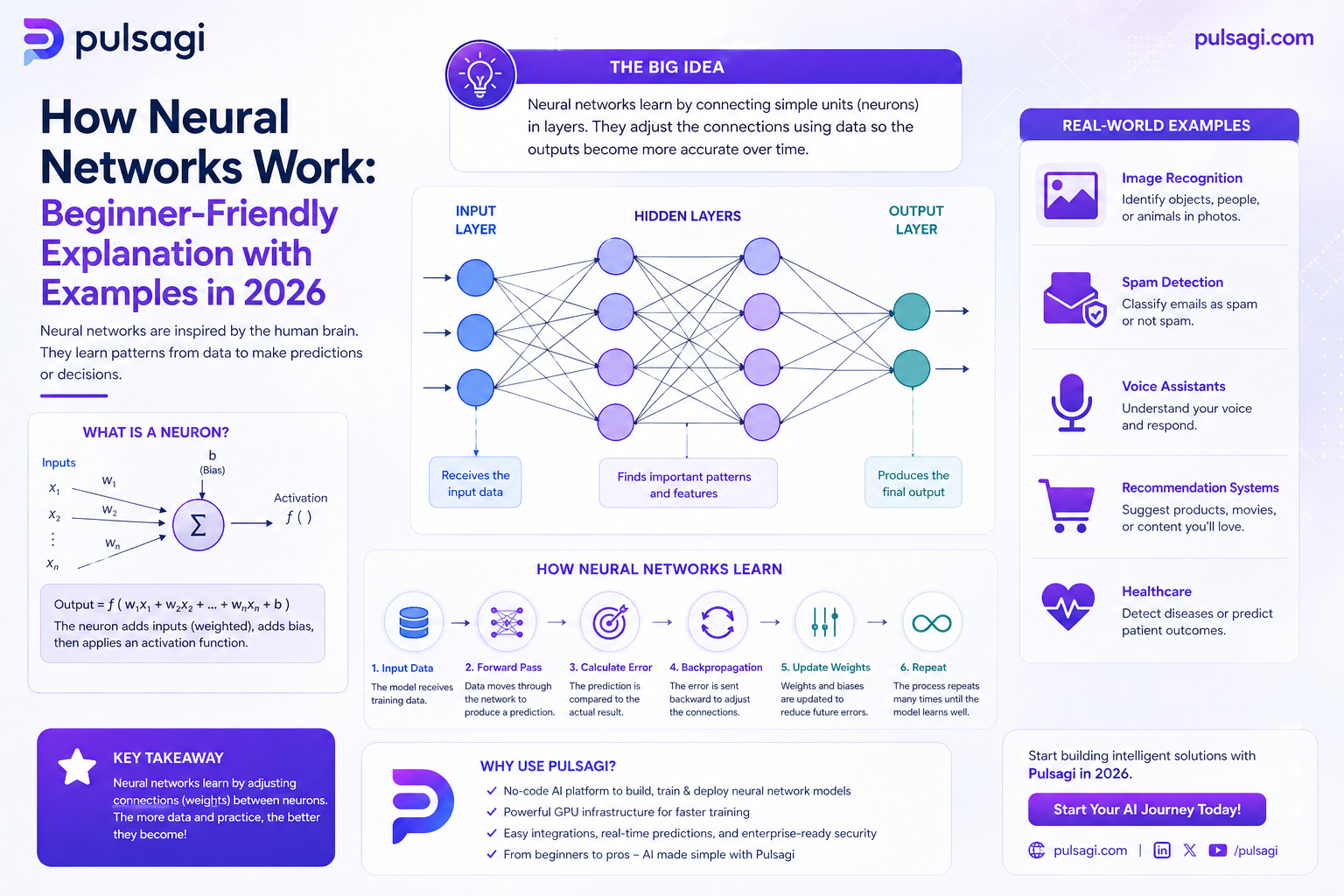
At the smallest level, a neural network node takes numbers in, multiplies them by weights, adds a bias, and passes the result through an activation function. At a larger level, many nodes are organized into layers. The first layer receives the input data, the middle layers transform it, and the final layer produces an output such as a class, score, or probability.
That sounds mechanical because it is. The impressive behavior comes not from any single node, but from many nodes learning useful internal structure together.
Why neural networks matter
Neural networks matter because they can model patterns that are difficult to capture with simple manual rules or linear feature crosses. That is why they became central to image recognition, speech systems, large language models, recommendation engines, and many other modern AI products.
Practical value: the more the raw input looks like pixels, tokens, sound waves, sequences, or rich behavior streams, the more likely a neural network becomes useful.
Key components
| Component | What it does | Why it matters |
|---|---|---|
| Inputs | The numbers the model receives, such as pixels, word ids, or business features. | Bad inputs limit everything downstream. |
| Weights | Learned parameters that control how strongly signals influence each node. | Training mainly means updating these weights. |
| Biases | Offsets that help nodes shift their activation thresholds. | They give the model more flexibility. |
| Hidden layers | Intermediate transformation layers between input and output. | These layers help the model learn richer representations. |
| Activation functions | Nonlinear functions such as ReLU, sigmoid, or softmax. | Without them, stacked layers behave too much like one linear transformation. |
| Loss function | Measures how wrong the prediction was. | The model needs a signal that tells it what to improve. |
| Optimizer | Updates weights based on gradients, such as SGD or Adam. | Controls how the model learns over time. |
How training works
Training a neural network can be described as a loop.
- Forward pass: the input travels through the network and produces a prediction.
- Loss calculation: the model compares its prediction with the correct answer.
- Backpropagation: the system computes how much each weight contributed to the error.
- Weight update: the optimizer nudges the weights in a direction that should reduce future loss.
- Repeat: the process runs over many examples and many epochs.
Examples
These practical examples make the mechanics more concrete.
From pixels to a number
A digit image is just a grid of pixel values. The network receives those values, transforms them through layers, and outputs probabilities for classes like 0, 1, 2, and so on. The highest probability becomes the prediction.
From text features to a class
A network can consume tokenized text or embeddings and learn patterns that suggest spam, such as suspicious phrases, link patterns, or language structure. The output layer may simply produce the probability of spam versus not spam.
From behavior to preference
In recommendation systems, a neural network can learn latent relationships between users, items, clicks, watch time, and sequence history. That internal representation is often more valuable than any single handcrafted feature.
From message to intent
A support classifier might take the subject line, body, product metadata, and previous interactions, then predict the best queue or intent category. That can reduce manual triage time significantly.
Admin and developer perspective
Neural networks are not only a modeling concept. They are also a systems decision.
| Role | What matters most | Practical takeaway |
|---|---|---|
| Business admin / IT admin | Cost, model behavior, explainability, monitoring, and responsible usage. | Neural networks should be treated as governed products, not isolated experiments. |
| Developer / ML engineer | Data quality, training loop design, model architecture, evaluation, and serving. | The architecture is only one piece; preprocessing and monitoring matter just as much. |
| Product team | User impact, latency, and reliability. | A slightly less accurate model that responds faster and is easier to govern may be the better product choice. |
Best practices
- Learn the flow before the jargon: forward pass, loss, backpropagation, update, repeat.
- Start with a simple architecture: beginners usually learn faster from a small dense network than from an oversized model.
- Use clear evaluation splits: separate training, validation, and test behavior early.
- Watch for overfitting: great training accuracy does not guarantee real-world value.
- Keep the baseline honest: sometimes a simpler non-neural model is enough.
- Use pretrained models when possible: transfer learning often beats training from scratch for practical teams.
Limitations
- They can be compute-heavy: especially for larger architectures and raw data.
- They can be harder to explain: this matters in regulated or high-stakes decisions.
- They can overfit quietly: strong training metrics can hide weak generalization.
- They depend heavily on data quality: noisy labels and poor preprocessing can waste a lot of effort.
Recommendation
If you are new, learn neural networks through a small supervised example first. A compact dense model on a simple dataset teaches the mechanics better than jumping immediately into a giant generative model stack.
For production teams, use neural networks when the data or task clearly benefits from learned representations. Otherwise, do not force them where simpler models are already good enough.