
Introduction
Your first AI model should not be judged by how flashy it sounds. It should be judged by whether you can explain the problem, trace the data, reproduce the result, and measure whether the model is useful.
This article was reviewed against official framework and educational documentation available on February 28, 2026. The guide uses a small supervised learning mindset because that is the shortest path to understanding model development without getting buried in unnecessary complexity.
What you are actually building
An AI model is not just code that calls a library. It is a learned function plus the surrounding workflow that feeds it data and measures whether it helps. For a beginner project, that usually means a classifier or regressor trained on labeled data.
A good first model is small enough that you can understand every part of it. That is why a tabular dataset plus scikit-learn is usually a better starting point than jumping straight into a giant foundation model stack.
Why this workflow matters
The workflow matters because beginners often focus on training code and ignore problem framing, leakage, and evaluation. Those parts decide whether the project is educational, useful, and repeatable.
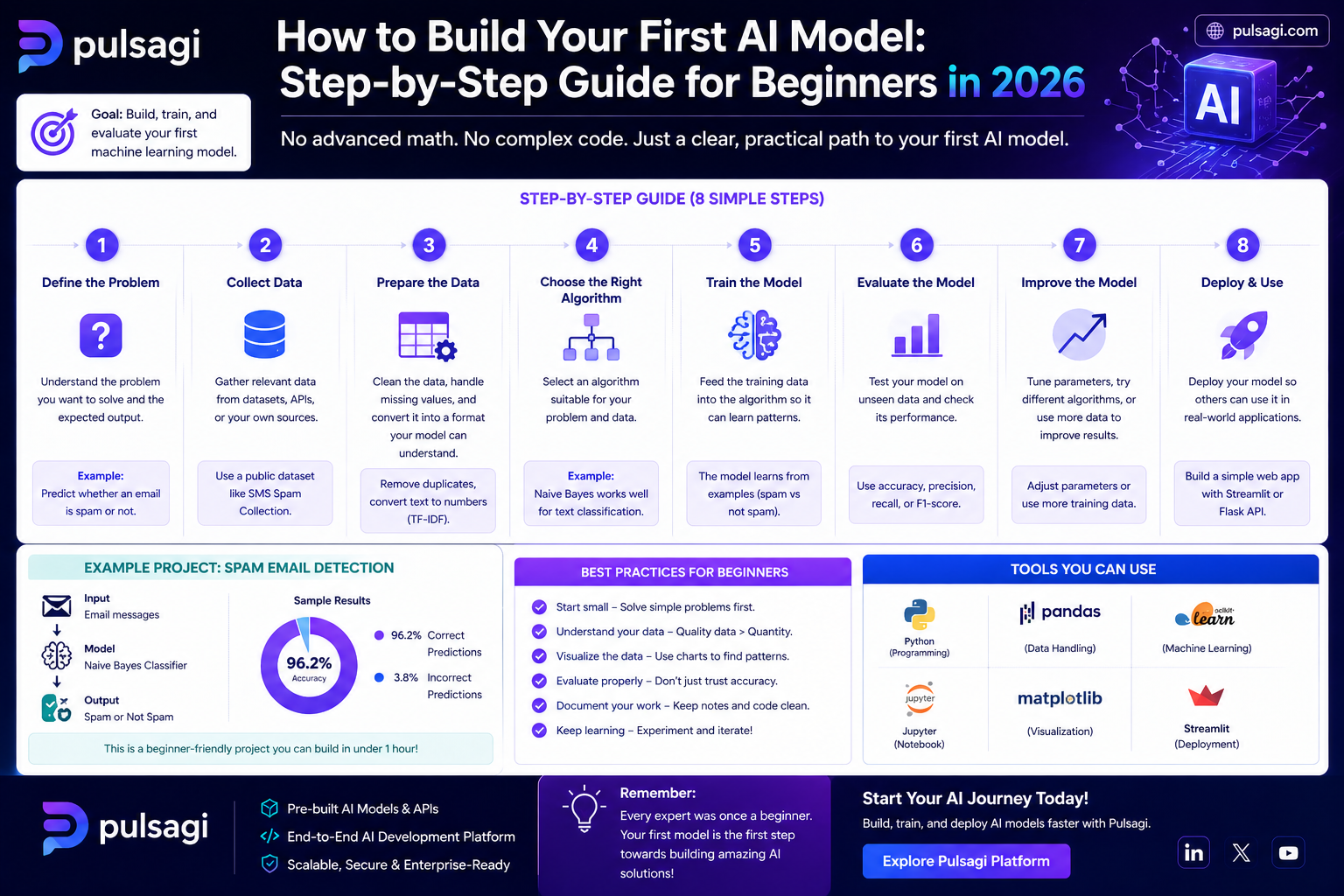
Step-by-step guide
| Step | What to do | Why it matters |
|---|---|---|
| 1. Define the problem | State exactly what you want to predict and how success will be measured. | A vague goal creates a vague model. |
| 2. Choose data | Start with a small, labeled, easy-to-understand dataset. | You need data you can inspect, not just consume blindly. |
| 3. Split the data | Create training and test sets before tuning too much. | This protects you from fooling yourself. |
| 4. Build a baseline | Train a simple model such as logistic regression. | You need a reference point before using anything more complex. |
| 5. Evaluate | Use metrics that match the task, such as accuracy, precision, recall, or RMSE. | Not all mistakes cost the same in real systems. |
| 6. Improve carefully | Tune preprocessing, model choice, or features only after reading the baseline behavior. | Optimization without understanding often wastes time. |
Simple first model with scikit-learn
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=0
)
model = make_pipeline(
StandardScaler(),
LogisticRegression()
)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))
This is a strong first project because it teaches splitting, preprocessing, fitting, and evaluation without introducing too many moving parts at once.
What a small neural workflow looks like
import keras
from keras import layers
model = keras.Sequential([
layers.Dense(64, activation="relu"),
layers.Dense(64, activation="relu"),
layers.Dense(3, activation="softmax")
])
model.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["sparse_categorical_accuracy"]
)
You do not need to start here, but this shows the next step once you understand the classical baseline workflow.
Practical examples
Predict whether a customer is likely to leave
Use product usage and account history as features, then predict a churn label. This is one of the most useful beginner mental models because it maps directly to real business value.
Predict whether a lead is likely to convert
A binary classification setup with structured CRM-style features is a classic first supervised learning project.
Classify pass or fail outcomes
A manufacturer could predict pass or fail using structured measurements from a production line. This is another beginner-friendly classification pattern.
Admin and developer perspective
| Role | What matters most | Practical advice |
|---|---|---|
| Business admin / IT admin | What action the model triggers, who approves it, and what data it uses. | Even a beginner model should have a clear ownership path and controlled usage. |
| Developer / data practitioner | Reproducibility, data cleaning, baseline creation, and metric selection. | Spend more time understanding the data and less time chasing exotic architectures too early. |
| Team lead | Learning speed and evidence of value. | A small successful model teaches more than a large unfinished one. |
Best practices
- Start with a narrow problem: "predict X from Y" is better than "build an AI system."
- Inspect the data manually: know what the columns mean and how labels are created.
- Keep a baseline: always compare improvements against the first simple model.
- Protect the test set: do not let it become part of the tuning loop.
- Match metrics to business reality: accuracy alone can be misleading.
- Document assumptions: data windows, feature definitions, and split logic should be written down.
Limitations
- A toy project is not production: deployment, monitoring, and retraining add another layer of work.
- Simple datasets can create false confidence: real business data is usually messier.
- Good metrics do not guarantee business fit: a model can be accurate and still operationally useless.
- Automation risk remains: humans still need oversight over how predictions are acted on.
Recommendation
If this is your first project, use Python, scikit-learn, and a small labeled dataset. Learn the full modeling loop once before jumping into deep learning or LLM-based systems. That foundation will make every later AI project easier to reason about.