
Introduction
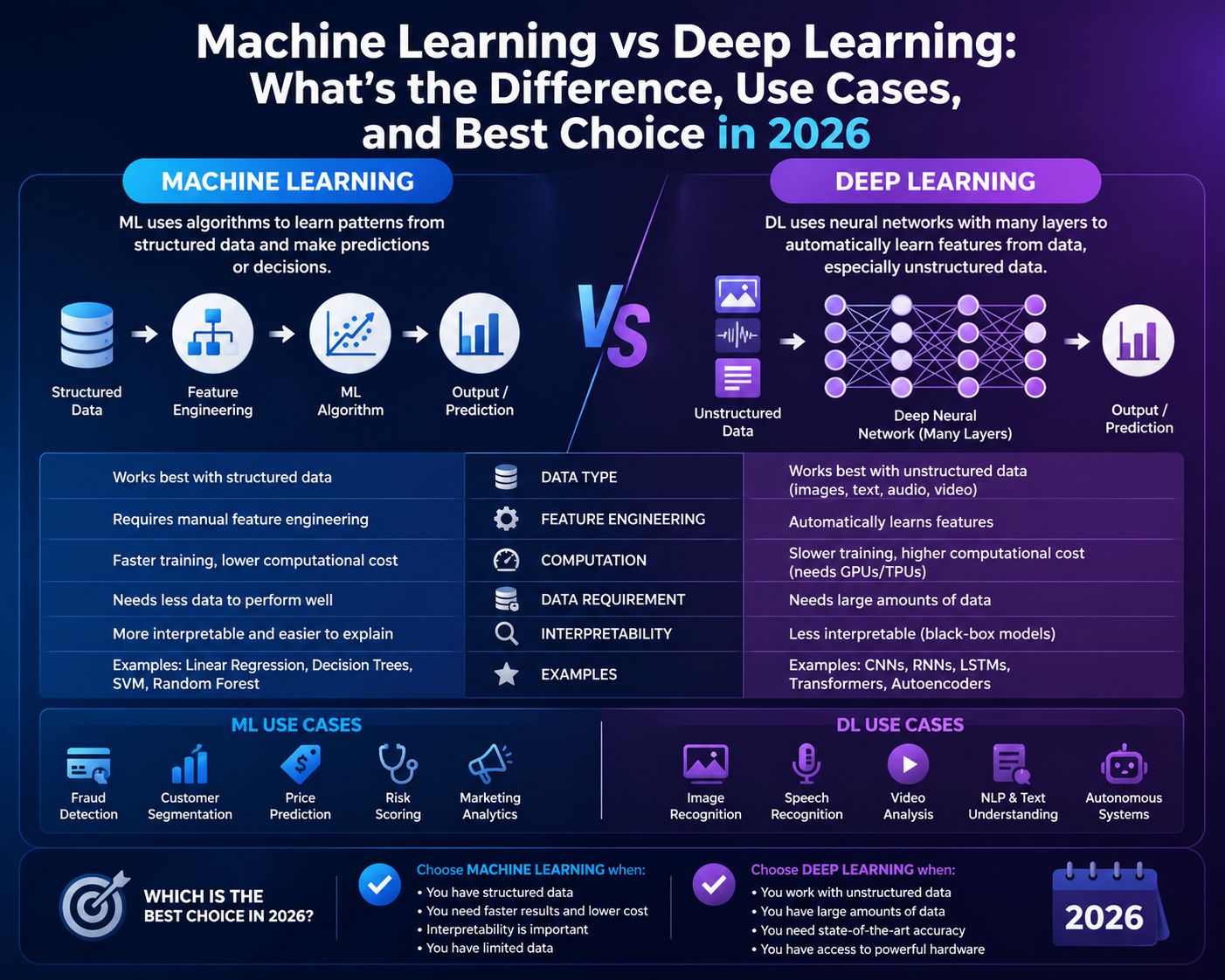
Machine learning is the broader category. It includes many techniques that learn from data, such as linear regression, logistic regression, decision trees, gradient boosting, support vector machines, and neural networks. Deep learning is a subset of machine learning built around multi-layer neural networks.
This article was reviewed against official educational and framework documentation available on March 14, 2026. The goal is practical clarity, not academic jargon. If you want one short answer, start with machine learning for structured business data and reach for deep learning when the signal is too complex for manual feature engineering, especially in text, vision, audio, and large-scale representation problems.
What machine learning is
Machine learning is the practice of training a model on historical data so it can make predictions or decisions on new data. In many business systems, the data is already organized into rows and columns: customer age, product category, contract value, support volume, click history, payment delay, and so on.
In that kind of environment, teams often create or select features deliberately. For example, instead of passing every raw transaction event to a model, they might create features such as average order value in the last 90 days, days since last login, or number of unresolved tickets. That is one reason machine learning projects can move quickly on enterprise data.
Why it matters: machine learning is not old-fashioned compared with deep learning. It remains the best default for a huge percentage of churn prediction, demand forecasting, anomaly detection, lead scoring, pricing, and risk models.
What deep learning is
Deep learning uses neural networks with multiple layers to learn internal representations automatically. Instead of asking a human to handcraft every useful feature, the model learns intermediate patterns during training. In image tasks, those patterns can move from edges to textures to shapes. In language tasks, they can move from tokens to context to meaning.
That does not mean deep learning replaces all machine learning. It means deep learning is a specialized answer to problems where the data is richer, noisier, or too complex for simple handcrafted signals to capture well.
Why it matters: deep learning is the foundation behind modern computer vision, speech recognition, language models, embeddings, recommendation systems, and multimodal AI experiences.
Key differences
The easiest way to understand the distinction is to compare the operating assumptions around data, training, explainability, and deployment.
| Dimension | Machine learning | Deep learning |
|---|---|---|
| Scope | Broad category covering many model families. | Subset of machine learning based on neural networks. |
| Typical data | Structured tabular data, engineered features, smaller datasets. | Images, text, audio, sequences, embeddings, large-scale signals. |
| Feature engineering | Usually more manual and domain-driven. | Usually more automatic through learned representations. |
| Compute cost | Often cheaper and faster to iterate. | Often heavier, especially during training. |
| Explainability | Usually easier to reason about and communicate to business teams. | Usually harder to explain in plain business terms. |
| Time to first result | Often faster for well-defined business prediction problems. | Often slower unless using a pretrained model or transfer learning. |
| Best fit | Forecasting, scoring, risk, anomaly detection, operational prediction. | Vision, NLP, speech, recommendation, generative AI, representation learning. |
Use cases and examples
The real question is not which term sounds more advanced. The real question is which approach makes the most sense for the job in front of you.
Machine learning is often the better first move
If a SaaS company wants to predict churn from account usage, ticket volume, renewal date, plan type, and billing behavior, a classical machine learning model is usually the right starting point. The data is structured, the features are interpretable, and the business wants answers quickly.
A gradient boosting model or logistic regression often gives a strong baseline faster than a custom deep model here.
Deep learning becomes much more natural
If the goal is to read invoices, identify layouts, classify extracted text, and handle messy scans, deep learning is a better fit because images and layout patterns are part of the task.
This is exactly the kind of problem where feature engineering by hand becomes brittle and expensive.
Both approaches can make sense
A team routing support tickets could use machine learning if it relies mostly on structured metadata such as product, customer tier, channel, or severity. But if the free-text description is the main signal, deep learning or pretrained NLP models usually become more valuable.
Hybrid architectures are common: metadata features plus text embeddings.
Machine learning is still dominant in many real systems
Fraud models often rely on fast scoring over transaction features, geography, device signals, history windows, and behavioral aggregates. Classical machine learning remains very strong because latency, governance, and operational explainability matter a lot.
Deep learning may still help around representation learning or graph-heavy patterns, but it is not automatically the first answer.
Deep learning is usually the obvious fit
Finding scratches, cracks, missing parts, or packaging defects from photos is much more naturally handled by deep learning because the model needs to understand spatial visual patterns.
Convolutional networks or vision transformers are far more practical than handcrafted image features for this class of problem.
Start simple before chasing complexity
Demand forecasting often starts well with classical machine learning or even statistical baselines. Many teams reach for deep learning too early, even when seasonality, promotions, and product metadata can already be captured in simpler models.
This is one of the most common places where teams can waste time by choosing a heavier model before validating the business baseline.
Admin and developer perspective
Teams that operate software should judge this choice operationally, not only academically.
| Role | What matters most | Machine learning angle | Deep learning angle |
|---|---|---|---|
| Business admin / IT admin | Approval flow, explainability, policy alignment, cost, and operational trust. | Usually easier to pilot and govern on business data. | Usually needs more care around infrastructure, monitoring, and model behavior review. |
| Developer / data engineer | Data pipeline shape, iteration speed, evaluation rigor, deployment surface. | Strong default for fast experimentation on structured datasets. | Stronger when using pretrained models, embeddings, or rich raw data. |
| Product owner | Time to value and measurable business improvement. | Often reaches useful production quality sooner. | May unlock higher ceilings, but usually with more delivery complexity. |
| Architecture lead | Platform fit, scalability, observability, and long-term maintainability. | Simpler stack and clearer fallback options. | Better fit for strategic AI capabilities like search, copilots, and perception systems. |
Best practices
- Start from the business question: choose the model family after the problem is clear, not before.
- Use the simplest credible baseline first: a strong baseline is more valuable than an ambitious but unvalidated architecture.
- Match the model to the data shape: tabular data often points to classical machine learning, while raw language and vision often point to deep learning.
- Do not ignore operational cost: training, inference speed, retraining cadence, and monitoring all matter.
- Protect against leakage: unrealistic evaluation is one of the fastest ways to overestimate success.
- Prefer transfer learning when appropriate: deep learning becomes more accessible when you can adapt a pretrained model instead of starting from scratch.
- Keep explainability proportional to business risk: the higher the risk, the stronger the need for validation and operational controls.
Limitations
Neither option is magic.
- Machine learning limits: handcrafted features can miss important nonlinear or raw-signal patterns.
- Deep learning limits: it can demand more data, more tuning, more compute, and more patience.
- Shared limit: both approaches can fail if labels are weak, data is biased, or the metric does not match the business outcome.
- Governance limit: neither approach automatically solves privacy, fairness, compliance, or monitoring challenges.
- Team limit: a sophisticated model does not help if the organization cannot operationalize it consistently.
Recommendation
If you are deciding between the two, start with machine learning unless the data itself strongly argues for deep learning.
Use machine learning for structured business prediction, scoring, and operational analytics. Use deep learning for language, vision, audio, embeddings, or situations where the representation must be learned from rich raw data. In many modern systems, the best answer is actually a combination: classical models for decisioning plus deep learning components for feature extraction or unstructured inputs.